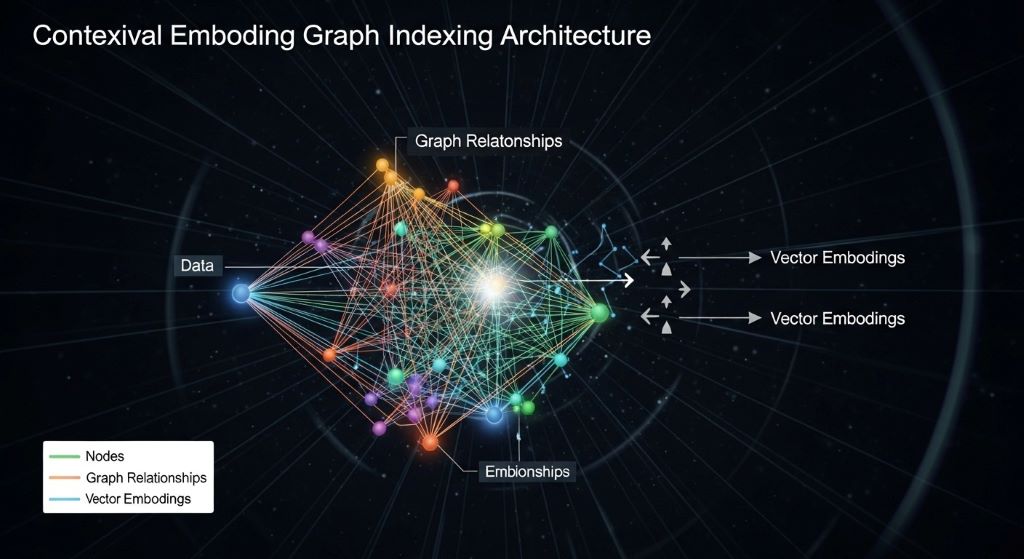
Contextual Embedding Graph Indexing
Modern data systems face a growing challenge. They must handle complex relationships while delivering fast, accurate results. Traditional databases struggle with this dual demand. However, a new approach is emerging that combines the best of both worlds. Index Marks explores how contextual embedding graph indexing transforms data retrieval by merging semantic understanding with relationship mapping.
This innovative method represents a significant leap forward in database technology. It allows organizations to understand not just what data exists, but how different pieces relate to each other. Additionally, it captures the meaning behind the data itself. This combination creates powerful search capabilities that were previously impossible to achieve.
Understanding the Foundation
Contextual embedding graph indexing builds on two established technologies. First, it uses embeddings to capture semantic meaning. These are mathematical representations of data that preserve context and relationships. Second, it employs graph structures to map connections between different data points. When combined, these technologies create a vector graph database that offers unprecedented search and retrieval capabilities.
The process begins with converting raw data into vector embeddings. These embeddings transform text, images, or other content into numerical arrays. Each array represents the semantic meaning of the content. Therefore, similar concepts end up close together in vector space, even if they use different words or formats.
How Graph Indexing Enhances Embeddings
Graph structures add another layer of intelligence to the system. They map explicit relationships between data points. For example, a graph might show that Document A references Document B, or that User X collaborated with User Y on Project Z. These connections provide valuable context that pure vector similarity cannot capture.
The indexing component optimizes both retrieval speed and accuracy. It creates efficient pathways through the graph structure. Meanwhile, it maintains quick access to similar vectors. This dual indexing approach ensures that searches return results that are both semantically relevant and contextually appropriate.
Real-World Applications
Many industries benefit from this technology. Healthcare organizations use it to connect patient records, research papers, and treatment protocols. Financial institutions apply it to detect fraud patterns while understanding transaction context. E-commerce platforms leverage it to recommend products based on both similarity and purchase history relationships.
Research institutions particularly value this approach. They can discover connections between studies that might share concepts but use different terminology. Furthermore, the graph structure reveals citation networks and collaboration patterns. This helps researchers identify influential work and potential partnerships.
Technical Advantages
The technology offers several key benefits over traditional approaches. First, it provides superior search accuracy by combining multiple relevance signals. Second, it scales efficiently because the indexing structure optimizes common query patterns. Third, it adapts to new data without requiring complete reindexing.
Query performance improves dramatically with proper implementation. The system can answer complex questions that require both semantic understanding and relationship awareness. For instance, it might find “research papers about neural networks that cite work from Stanford University.” This query demands both concept matching and graph traversal.
According to research from MIT Technology Review, hybrid database systems that combine different indexing approaches show significant performance improvements over single-method systems. They reduce query times while increasing result relevance.

Implementation Considerations
Organizations planning to adopt this technology should consider several factors. Data preparation requires careful attention. Content must be cleaned and structured appropriately. Additionally, relationships between data points need clear definition and documentation.
The choice of embedding model matters significantly. Different models excel at different tasks. Some perform better with short text, while others handle long documents more effectively. Therefore, organizations should test multiple options with their specific data types.
Graph design also requires thoughtful planning. Too few connections limit the system’s ability to find related information. However, too many connections can slow down queries and introduce noise. The optimal structure depends on the use case and query patterns.
Integration with Existing Systems
Most organizations already have established databases and workflows. Contextual embedding graph indexing can enhance these systems rather than replace them. Many implementations use it as a layer on top of existing data stores. This approach preserves current investments while adding new capabilities.
The integration process typically involves several steps. First, data flows from source systems into the embedding generation pipeline. Next, the system builds and maintains the graph structure. Finally, a query layer translates user requests into efficient searches across both the vector and graph indices.
Future Developments
This field continues to evolve rapidly. Researchers are developing more efficient embedding models that require less computational power. New graph algorithms improve traversal speed and reduce memory requirements. Moreover, automated systems are emerging that can suggest optimal graph structures based on data patterns.
Machine learning models increasingly leverage these hybrid structures for training and inference. They can access both factual knowledge from graphs and semantic understanding from embeddings. This combination produces more accurate and contextually aware results.
Conclusion
Contextual embedding graph indexing represents a significant advancement in data management and retrieval. It combines semantic understanding through vector embeddings with relationship mapping through graph structures. This hybrid approach delivers superior search accuracy, better scalability, and more nuanced results than traditional methods.
Organizations across industries are adopting this technology to unlock new insights from their data. The implementation requires careful planning and data preparation. However, the benefits in terms of search quality and analytical capabilities make it a worthwhile investment. As the technology matures, it will become increasingly accessible to organizations of all sizes.
Frequently Asked Questions
What is the main difference between traditional databases and contextual embedding graph indexing?
Traditional databases rely on exact matches and predefined relationships. Contextual embedding graph indexing understands semantic meaning and can find relevant information even when different terms are used. It also maps complex relationships between data points automatically.
How long does it take to implement a vector graph database system?
Implementation time varies based on data volume and complexity. Small projects might take a few weeks, while enterprise deployments can require several months. Most of this time involves data preparation and testing rather than actual system setup.
Can this technology work with unstructured data?
Yes, contextual embedding graph indexing excels with unstructured data. It can process text documents, images, audio files, and other formats. The embedding process converts this unstructured content into searchable vectors while maintaining semantic meaning.
What are the hardware requirements for running these systems?
Basic implementations can run on standard servers. However, large-scale deployments benefit from GPU acceleration for embedding generation. Cloud providers offer specialized services that handle the infrastructure requirements automatically.
Is contextual embedding graph indexing suitable for small businesses?
Many cloud-based solutions make this technology accessible to businesses of all sizes. Small organizations can start with managed services that require minimal technical expertise. They pay only for the resources they use, making it cost-effective even for limited budgets.
Related Topics:
Best Apps That Teach Emotional Intelligence to Kids: A Parent’s Journey
Amazon Kindle Scribe Tablet Alternative: What’s the Best Choice?